나는 아래글의 내용에 몇가지 의문을 제기한다.
개발자의 성과를 측정하는 지표가. Code 에 한정되어 있다는 것이다.
물론 틀린말은 아니다.
아니. 틀렸다.
우리는 생각을 확장 시켜야 한다.
이런 생각을 해 보았는가?
” 개발자가 목표하는 바가 무엇인가? “
” 어떤 지시를 받고, 이런 코드를 생산하고 있는가? “
코드의 생산성이 개발자의 성과가 아니다.
회사의 성과 기준은. 개발자에게 지시했던 요구사항이 기준이 되어야 한다.
어째서, 이미 틀렸을 수도 있는 코드를 가지고 지표를 만들고 있는가?
출처 : https://medium.com/proofer-blog/%EB%8F%84%EB%9D%BC-%EB%A9%94%ED%8A%B8%EB%A6%AD-dora-metrics-%EC%A7%80%ED%91%9C%EB%8A%94-5%EA%B0%9C%EB%8B%A4-34f06d73b197 도라 메트릭(DORA Metrics) 지표는 5개다?2020년 The ROI of DevOps Transformation 를 통하여 접하셨던 분들은 DORA Metrics 는 다음과 같은 총 4개의 지표로 이루어진다고 알고 있을 수 있습니다.medium.com
2020년 The ROI of DevOps Transformation 를 통하여 접하셨던 분들은 DORA Metrics 는 다음과 같은 총 4개의 지표로 이루어진다고 알고 있을 수 있습니다.
- 배포 빈도(Deployment frequency, DF) — 프로덕션 환경으로 배포하는 빈도
- 변경 리드 타임(Lead time for changes, LTC) — 새로운 코드를 개발하고 프로덕션에 배포하기까지 소요되는 시간
- 변경 실패율(Change failure rate, CFR) — 프로덕션 배포시에 오류나 다운타임이 발생하는 비율
- 실패한 배포 복원 시간(Failed deployment recovery time, FDRT) —프로덕션 배포로부터 발생한 오류나 다운타임을 복구하는 데 걸리는 시간
뭔가 이상한게 하나 있죠. 이제 “MTTR” 이 아닙니다.
MTTR 이라는 용어는 “M 은 Median 인가요 아니면 Mean인가요?” 나 “배포 이전부터 있던 오류가 발견되면 어떻게 해야하죠?”같은 혼란을 야기했습니다. 때문에 “MTTR”로 축약되는 보다 일반적인 “time to recovery” 대신 “Failed deployment recovery time”이라는 용어를 사용하게 되었습니다.
2021년에 DORA 팀은 조직 성과에 영향을 미칠 수 있는 항목에 다섯 번째 측정항목인 “안정성” 을 추가했습니다(Accelerate: State of DevOps 2021).

Four key metrics 의 보조 지표로 제안 되었던 “가용성”의 확장입니다.
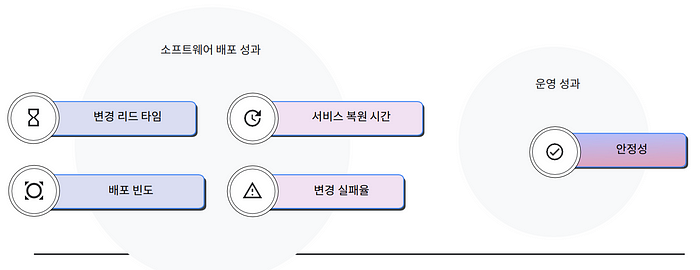
DORA 팀은 가용성은 안정성 엔지니어링의 일부분이기 때문에 가용성, 대기 시간, 성능 및 확장성이 더 광범위하게 표시되도록 안정성으로 측정을 확장했습니다.
경우에 따라 이를 “신뢰성” 으로 번역하기도 합니다만, DORA 팀이 속해있는 Google Cloud 의 공식 번역에 따르면 “안정성” 입니다.
또한 성과 수준이 다양한 조직들이 운영 성과의 우선순위를 정할 때 안정성을 측정한 조직들이 더 나은 결과를 얻을 수 있다는 것을 발견했습니다. 그래서 도라 메트릭(DORA Metrics) 는 총 5개의 지표로 이루어집니다.
- 배포 빈도(Deployment frequency, DF) — 프로덕션 환경으로 배포하는 빈도
- 변경 리드 타임(Lead time for changes, LTC) — 새로운 코드를 개발하고 프로덕션에 배포하기까지 소요되는 시간
- 변경 실패율(Change failure rate, CFR) — 프로덕션 배포시에 오류나 다운타임이 발생하는 비율
- 실패한 배포 복원 시간(Failed deployment recovery time, FDRT) — 프로덕션 배포로부터 발생한 오류나 다운타임을 복구하는 데 걸리는 시간
- 안정성(Reliability) — 운영하는 소프트웨어에 대한 계획과 제안을 지킬 수 있는 정도